1.5.2. Что такое Дерево Данных?
Дерево данных - это иерархическая структура для хранения данных, состоящая из списков. Деревья данных создаются, когда компонент grasshopper структурируется, чтобы принять набор данных и вывести множественные наборы данных. Grasshopper работает с этими новыми данными, размещая их в под-списки. Эти под-списки работают таким же образом, как и структуры папок на вашем компьютере, а именно, чтобы получить доступ к индексированным элементам требуется пройти по путям, которые проинформированы своим поколением родительских списков и их собственными под-индексами.
Это становится возможным иметь множественные списки данных внутри одного параметра. Как только становятся доступны множественные списки, возникает необходимость в способе распознавания каждого отдельного списка. Дерево данных, по сути, список списков или, иногда, список списков списков (и т.д.).
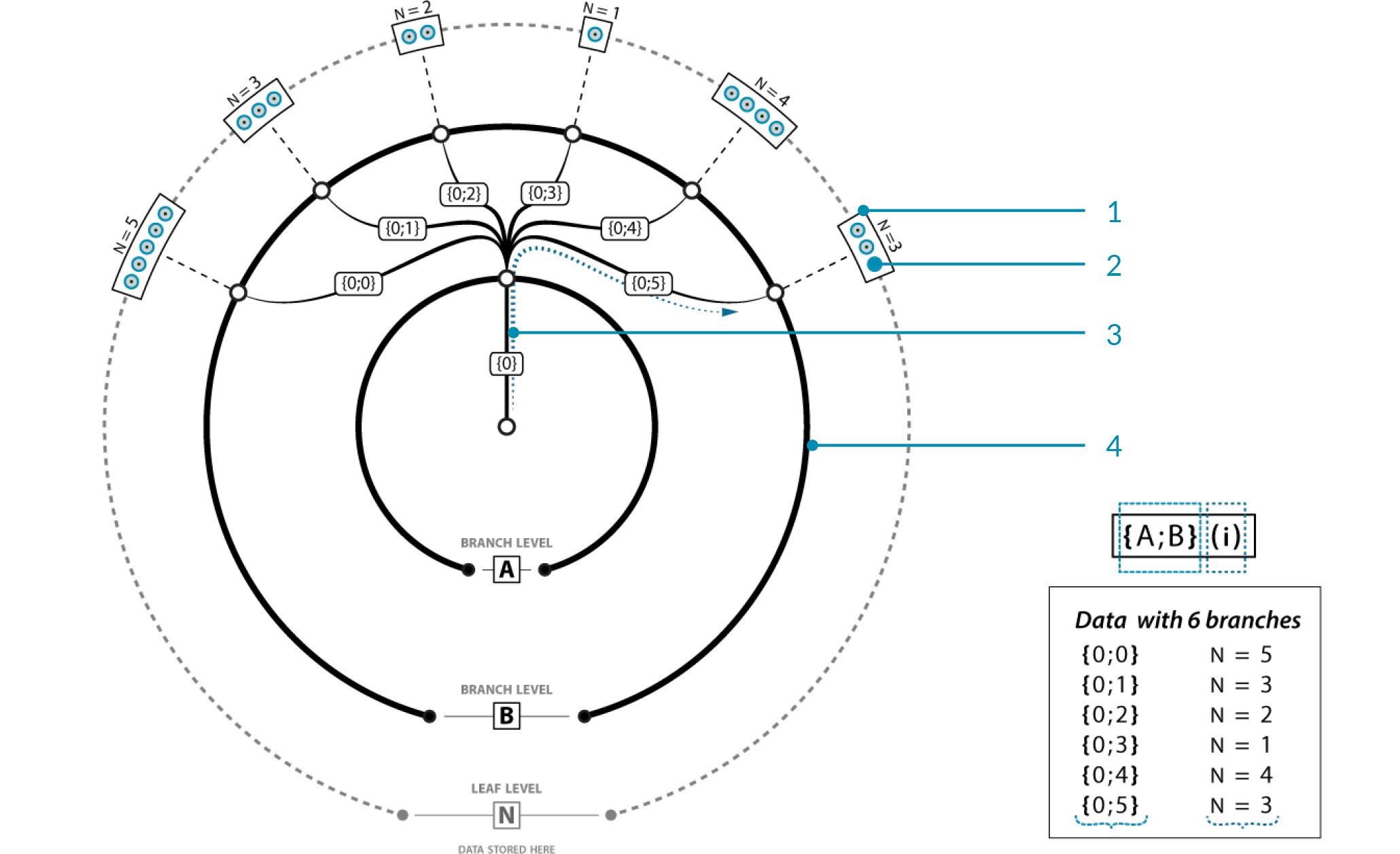
В изображении выше, вы видите одну главную ветку (можете называть ее стволом, но так как тут возможно наличие множества главных веток, то этот термин может быть неточным) пути {0}. Этот путь не содержит данных, но имеет 6 под-веток. Каждая из этих под-веток наследует индекс родительской ветки {0} и добавляет свой собственный под-индекс (0, 1, 2, 3, 4 и 5, соответственно). Будет неправильно называть это число "индекс", потому что это подразумевает только одно число. Возможно, лучше называть это "путь", так как он похож на структуру папок на диске. У каждой из этих под-веток мы встречаем какие-либо данные. Каждый элемент данных, таким образом, часть одной (и только одной) ветки в дереве, каждый элемент имеет индекс, который указывает его расположение внутри ветки. У каждой ветки есть свой путь, который указывает ее расположение внутри дерева.
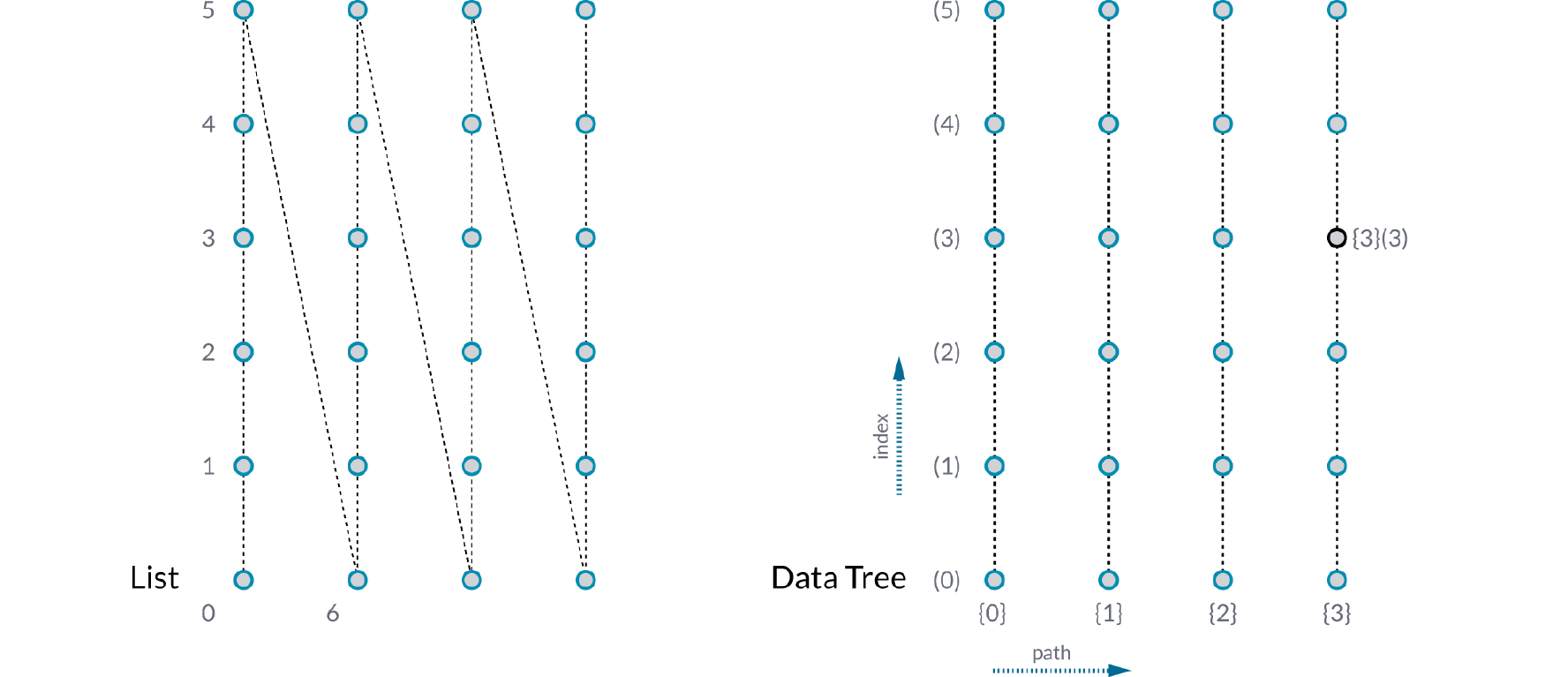
Изображение ниже иллюстрирует разницу между списком и деревом данных. Слева, массив из четырех колонок по 6 точек каждая - это все, что содержится в одном списке. Первая колонка пронумерована 0-5, вторая 6-11 и т.д. Справа расположен тот же самый массив точек, содержащихся в дереве данных. Дерево данных - это список из четырех колонок, где каждая колонка - это список из шести точек. Индекс каждой точки это (номер колонки, номер ряда). Это намного более полезный способ организации этих данных, потому что вы можете легко получить доступ и работать со всеми точками в данном ряду или колонке, удалить каждый второй ряд точек, соединить чередующиеся точки и прочее.
1.5.2.1. ВИЗУАЛИЗАЦИЯ ДЕРЕВА ДАННЫХ
Файлы упражнения, которые сопровождают этот раздел: Download
Из-за их комплексности понять, как работают деревья данных, может быть затруднительно. У Grasshopper есть несколько инструментов для визуализации и понимания данных, хранящихся в дереве.
The Param Viewer Param Viewer (Params/Util/Param Viewer) позволяет визуализировать данные в текстовом формате и в виде дерева. Соедините любой выход, содержащий данные, с входом Param Viewer. Чтобы данные отобразились в виде дерева, кликните правой клавишей мыши по Param Viewer и выберите "draw tree". В этом примере, Param Viewer соединен с выходом Points (P) компонента Divide Curve, который разделил 10 кривых на 10 сегментов каждую кривую. Десять веток соответствуют десяти кривым, каждая содержит список из 11 точек, которые являются точками деления кривой.
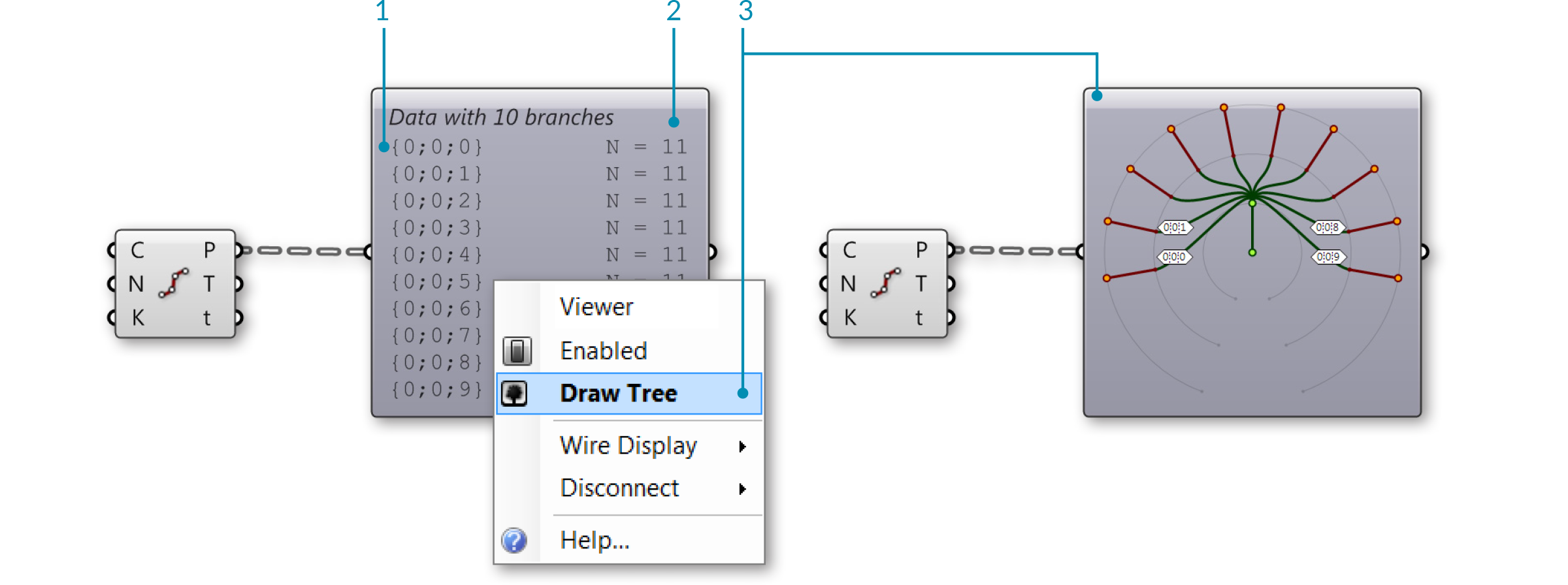
- Путь каждого списка
- Число элементов в каждом списке
- Выберите "Draw Tree" для отображения дерева данных
Если подсоединить панель к тому же самому выходу, то она отобразит десять списков из 11 элементов каждый. Вы также можете заметить, что каждый элемент является точкой, определяемой тремя координатами. Путь отображается поверх каждого списка и соответствует путям, перечисленным в Param Viewer

- Путь
- Список из 11 элементов
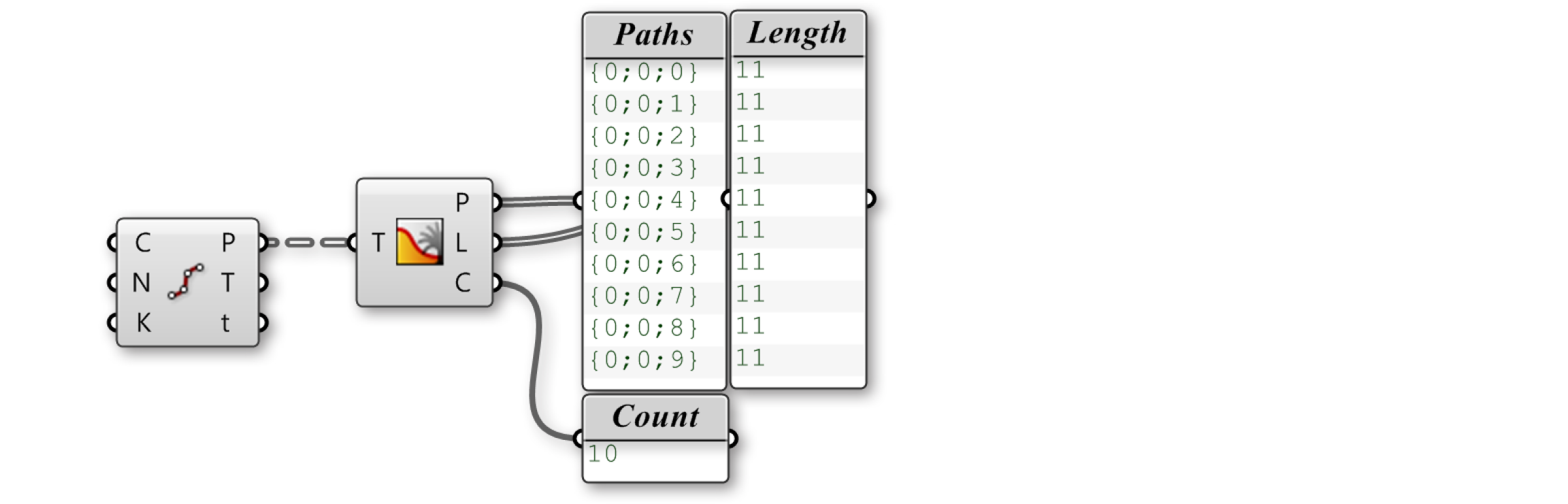
Tree Statistics Компонент Tree Statistics (Sets/Tree/Tree Statistics) выдает обратно некоторую статистику Дерева Данных, включая:
- P - все пути дерева
- L - длина каждой ветки дерева
- C - число путей и веток у дерева
Если соединить выход Points того же самого компонента Divide Curve, мы сможем показать все пути, длины и число панелей. Этот компонент полезен тем, что он разделяет статистику на три выхода, позволяя просматривать только один, которые необходим.
Оба компонента Param Viewer и Tree Statistics полезны для визуализации изменений в структуре Дерева данных. В следующем разделе, мы рассмотрим некоторые операции, которые могут быть выполнены, чтобы изменить эту структуру.