1.4.3. Abgleichung von Datenströmen
Beispiele zu diesem Abschnitt: http://grasshopperprimer.com/appendix/A-2/1_gh-files.html
Datenabgleich ist ein Problem ohne saubere Lösung. Es taucht auf, wenn eine Komponente Zugriff auf Eingabeparameter mit unterschiedlicher Anzahl von Datenelementen hat. Die Veränderung des Datenabgleichalgorithmus kann zu sehr verschiedenen Ergebnissen führen.
Stelle Dir eine Komponente vor, die eine Linie zwischen Punkten zeichnet. Sie wird zwei Eingabeparameter haben, die beide Punktkoordinaten beinhalten (Liste A und Liste B):
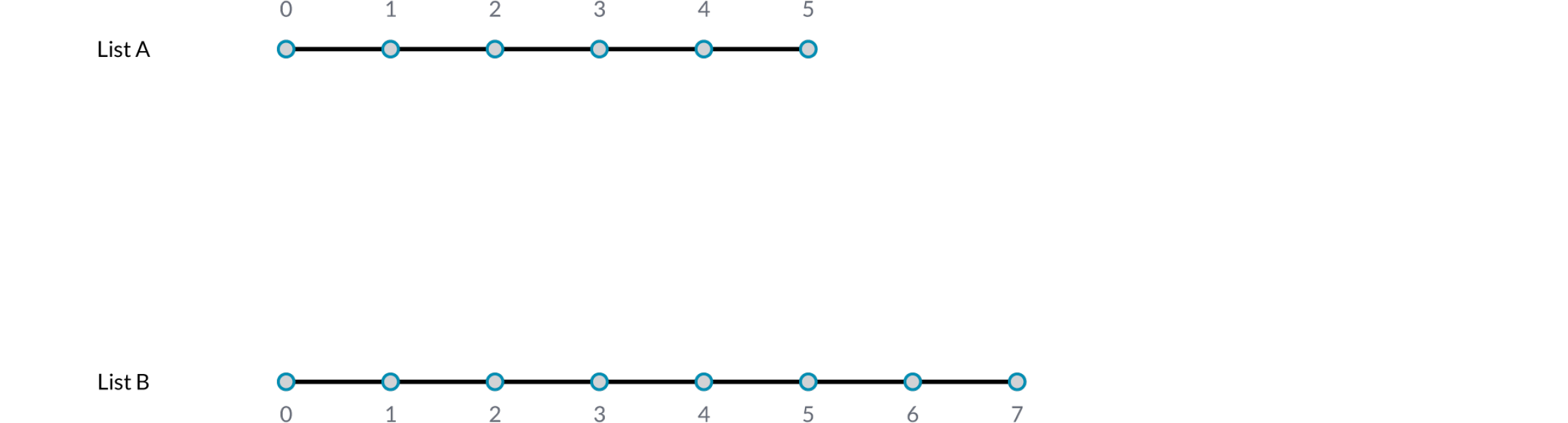
Wie Du hier sehen kannst gibt es verschiedene Arten die Linien von einer Menge von Punkten zur anderen zu zeichnen. Neu in Grasshopper 0.9 sind die drei Komponenten zum Datenabgleich, die im "Sets/List" Reiter gefunden werden: "Shortest List", "Longest List", und "Cross Reference". Diese neuen Komponenten erlauben grössere Flexibilitaet der drei grundlegenden Datenabgleichalgorithmen. Ein Rechtsklick auf die jeweilige Komponente gibt die Möglichkeit mehrere Datenabgleichoptionen aus einem Menu auszuwählen.
Der einfachste Weg ist es die Elemente des Eingabeparameters eins zu eins zu verbinden bis der Datenstrom abreisst. Dis nennt man “Shortest List” Algorithmus:
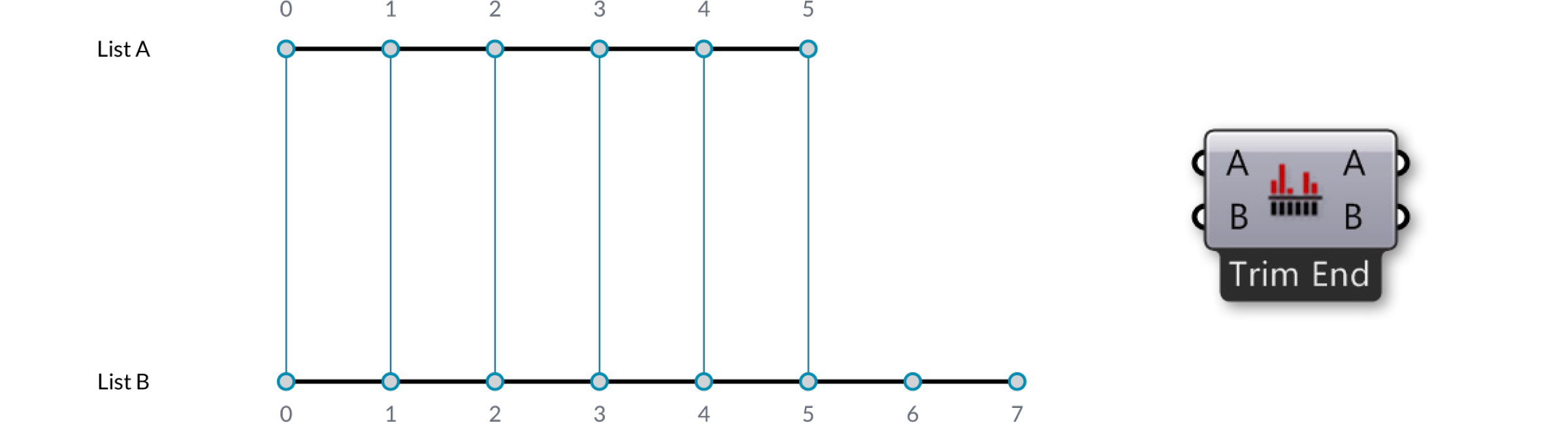

Wähle eine Option für den Datenabgleichalgorithmus aus dem Komponentenmenu, indem Du auf die Komponente rechtsklickst.
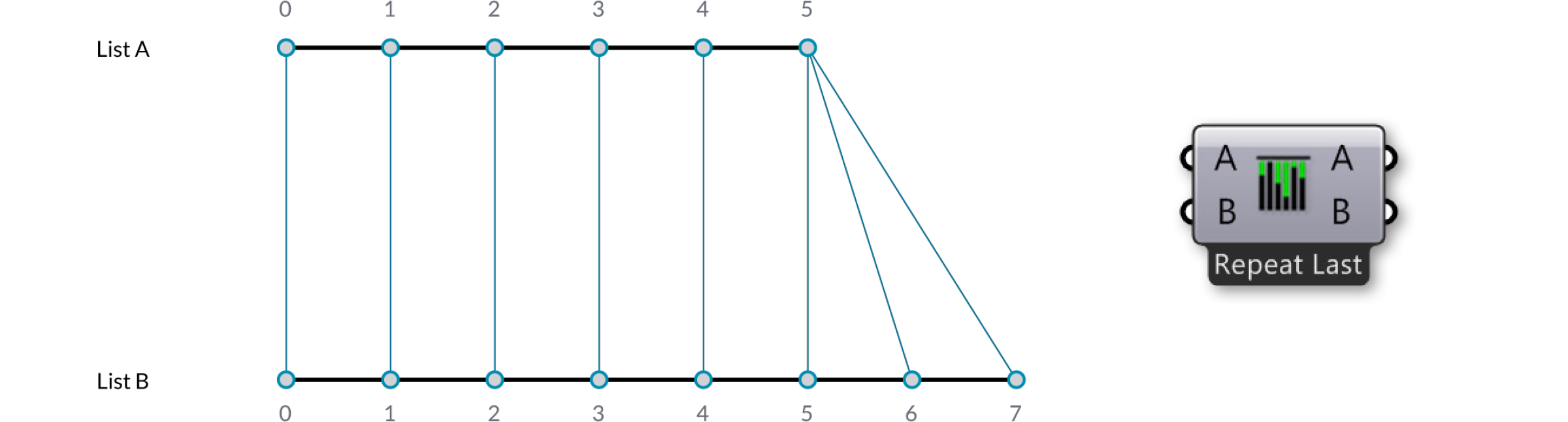
Der “Longest List” Algorithmus verbindet Elemente des Eingabeparameters bis beide Datenströme abreissen. Dis ist das Standardverhalten der Komponente:
Schliesslich macht die “Cross Reference” Methode alle möglichen Verbindungen:
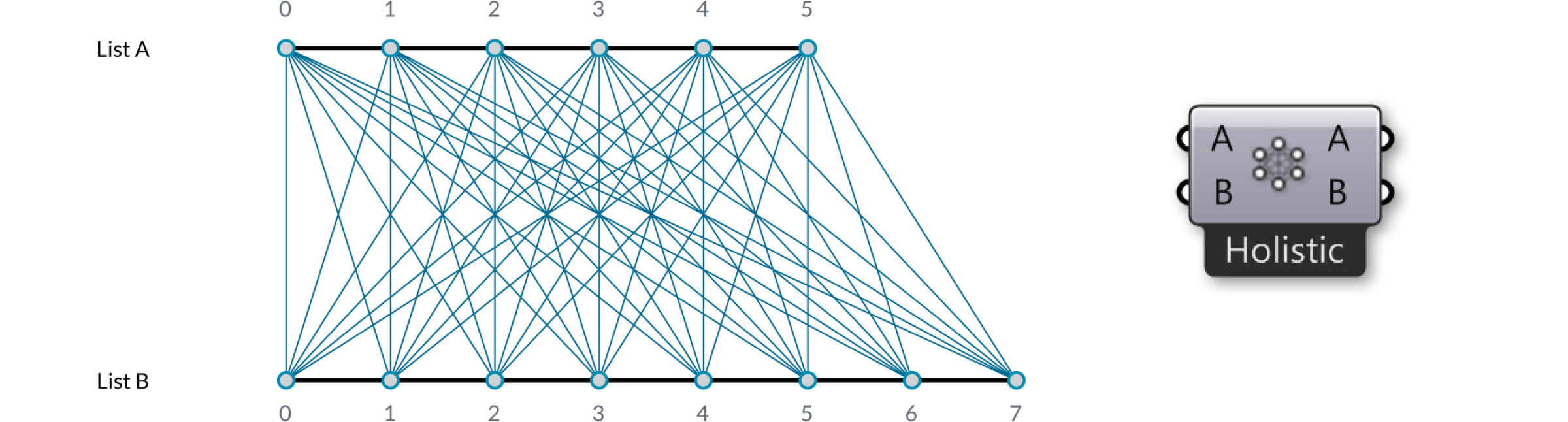
Dies ist grundsätzlich gefährlich, da die Anzahl von Elementen im Ausgabeparameter enorm sein kann. Das Problem wird offensichtlicher, wenn mehr Eingabeparameter involviert sind und die volatile Datenvererbung die Daten vervielfacht, aber die Logik der Definition dieselbe bleibt.
Lass uns die "Shortest List" Komponente etwas genauer ansehen:
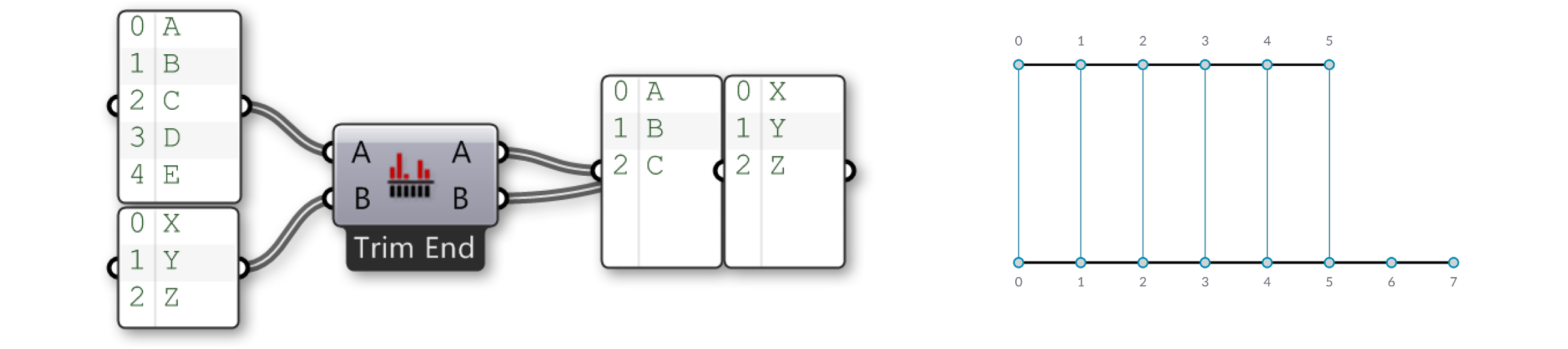
In diesem Fall haben wir zwei Eingabelisten {A,B,C,D,E} und {X,Y,Z}. Benutzen wir die "Trim End" Option, so werden die beiden letzten Elemente der ersten Liste ausser acht gelassen, so dass die beiden Listen die gleiche Länge haben.
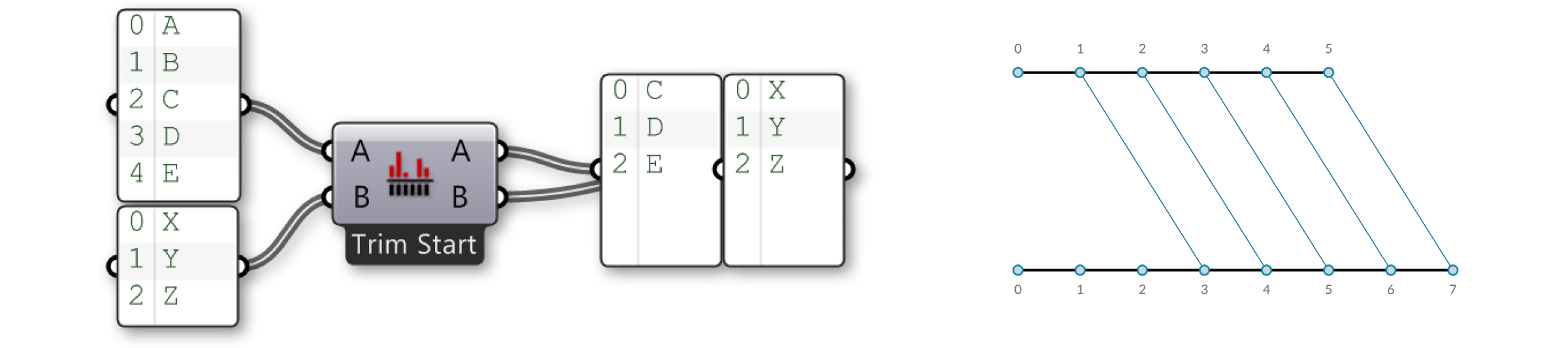
Die "Trim Start" Option lässt die beiden ersten Elemente der ersten Liste ausser acht, so dass die beiden Listen die gleiche Länge haben.
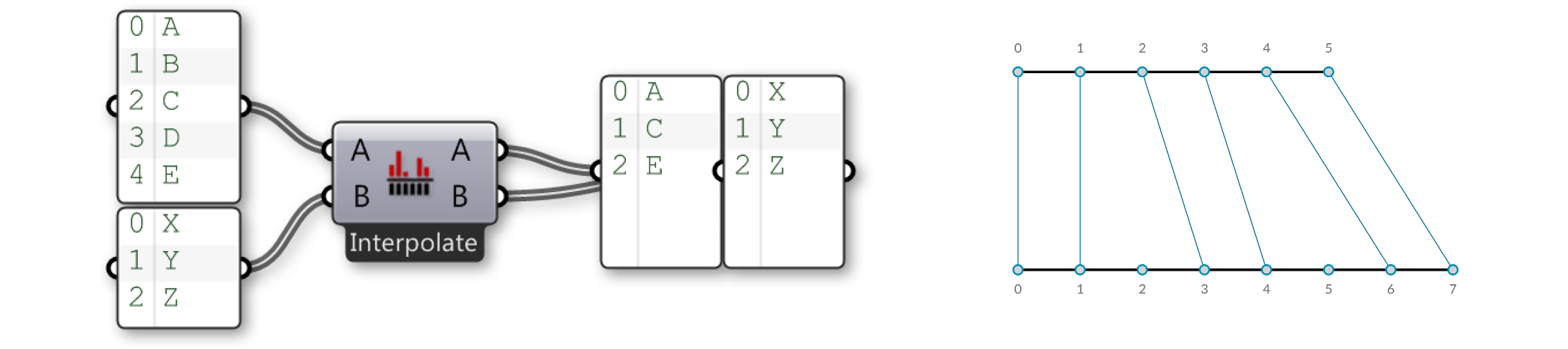
Die "Interpolate" Option überspringt das zweite und vierte Element der ersten Liste. Nun sehen wir uns die "Cross Reference" Komponente an:

Nun haben wir zwei Eingabelisten {A,B,C} und {X,Y,Z}. Normalerweise würde Grasshopper über beide Listen iterieren und die Kombinationen {A,X}, {B,Y} und {C,Z} bilden. Hier jedoch werden sechs weitere Kombinationen berücksichtigt: {A,Y}, {A,Z}, {B,X}, {B,Z}, {C,X} und {C,Y}. Wie Du sehen kannst, besteht die Ausgabe der "Cross Reference" Komponente momentan aus neun Permutationen.
Wir können das Verhalten der "Cross Reference" Komponente in einer Tabelle darstellen. Die Zeilen repräsentieren die erste Liste und ihre Elemente, die Spalten die zweite. Wenn wir alle möglichen Permutationen erzeugen, wird die Tabelle in jeder Zelle einen Punkt haben, da jede Zelle eine einzigartige Kombination von zwei Quellelementen darstellt.

Manchmal jedoch möchtest Du nicht alle möglichen Permutationen erhalten. Manchmal willst Du bestimmte Zonen aussparen, weil sie bedeutungslose oder falsche Berechnungen liefern würden. Ein häufiges Ausschlussprinzip ist es alle Zellen auszusparen, die auf der Diagonale der Tabelle liegen (diese Option ist als "diagonal" in der "Cross Reference" Komponente enthalten) und schliesst die Kombinationen {0,0}, {1,1}, {2,2} und {3,3} aus. Wenn wir dies auf unsere Listen {A,B,C}, {X,Y,Z} anwenden, würden wir erwarten, die Kombinationen {A,X}, {B,Y} und {C,Z} vorzufinden:
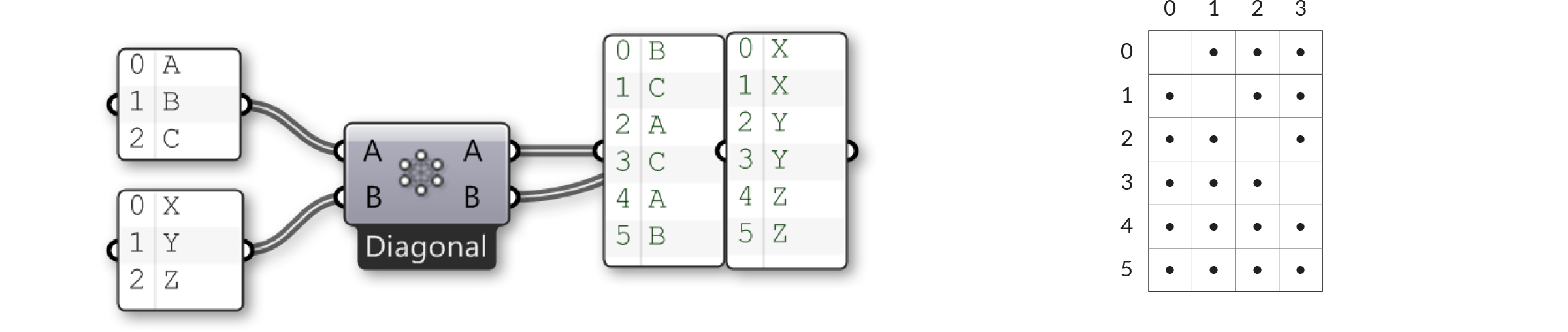
Die Regel für den diagonalen Datenabgleich ist: “Überspringe alle Permutationen, in denen die Elemente jeweils den selben Listenindex haben”. ‘Coincident’ Datenabgleich ist derselbe Algorithmus wie Datenabgleich, wenn zwei Listen als Eingabe vorhanden sind, aber die Regel ist etwas anders: “Lasse alle Permutationen aus, in denen zwei Elemente die selben Listenindices aufweisen”.
Die vier verbleibenden Datenabgleichalgorithmen sind alle Variationen desselben Themas. ‘Lower triangle’ Datenabgleich wendet folgende Regel an: “Lasse alle Permutationen aus, in denen der Index eines Elementes niedriger ist als der Index des Elementes in der nächsten Liste”, was zu einem leeren Dreieck führt, das aber Elemente auf der Diagonale beinhaltet.
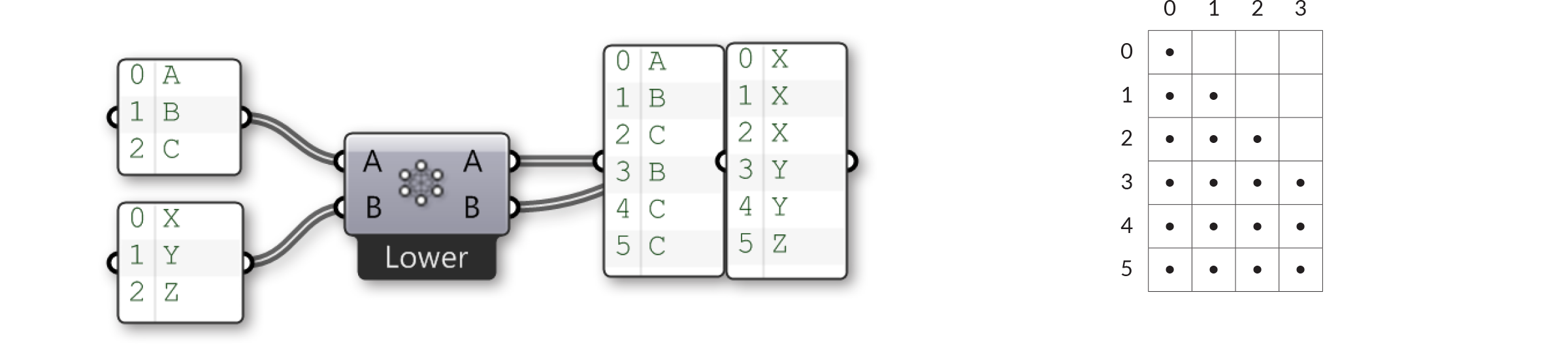
‘Lower triangle (strict)’ Datenabgleich geht einen Schritt weiter, indem er auch die Elemente auf der Diagonale ausspart:

‘Upper Triangle’ und ‘Upper Triangle (strict)’ spiegeln das Verhalten des vorher beschriebenen Algorithms, was zu einem leeren Dreieck auf der anderen Seite der Diagonale führt.